Guardrails
A layered guardrail system around every agent run, from deterministic checks to policy agents, with violations your process or case can handle.
What it is
Guardrails are a safety layer that wraps the input and output of an agent. Rather than a single mechanism, they are a set of guardrail types you combine to suit each use case, ranging from fast deterministic checks to an LLM-based policy judge, with a clear choice of what happens when one is triggered.
A guardrail can sit on the way in, validating or cleaning what reaches the model, or on the way out, checking what the model produced before it is used. Deterministic and service-based guardrails need no model call at all, and an input guardrail that triggers can skip the LLM call entirely, so unsafe or out-of-scope requests never reach the model in the first place.
What’s included:
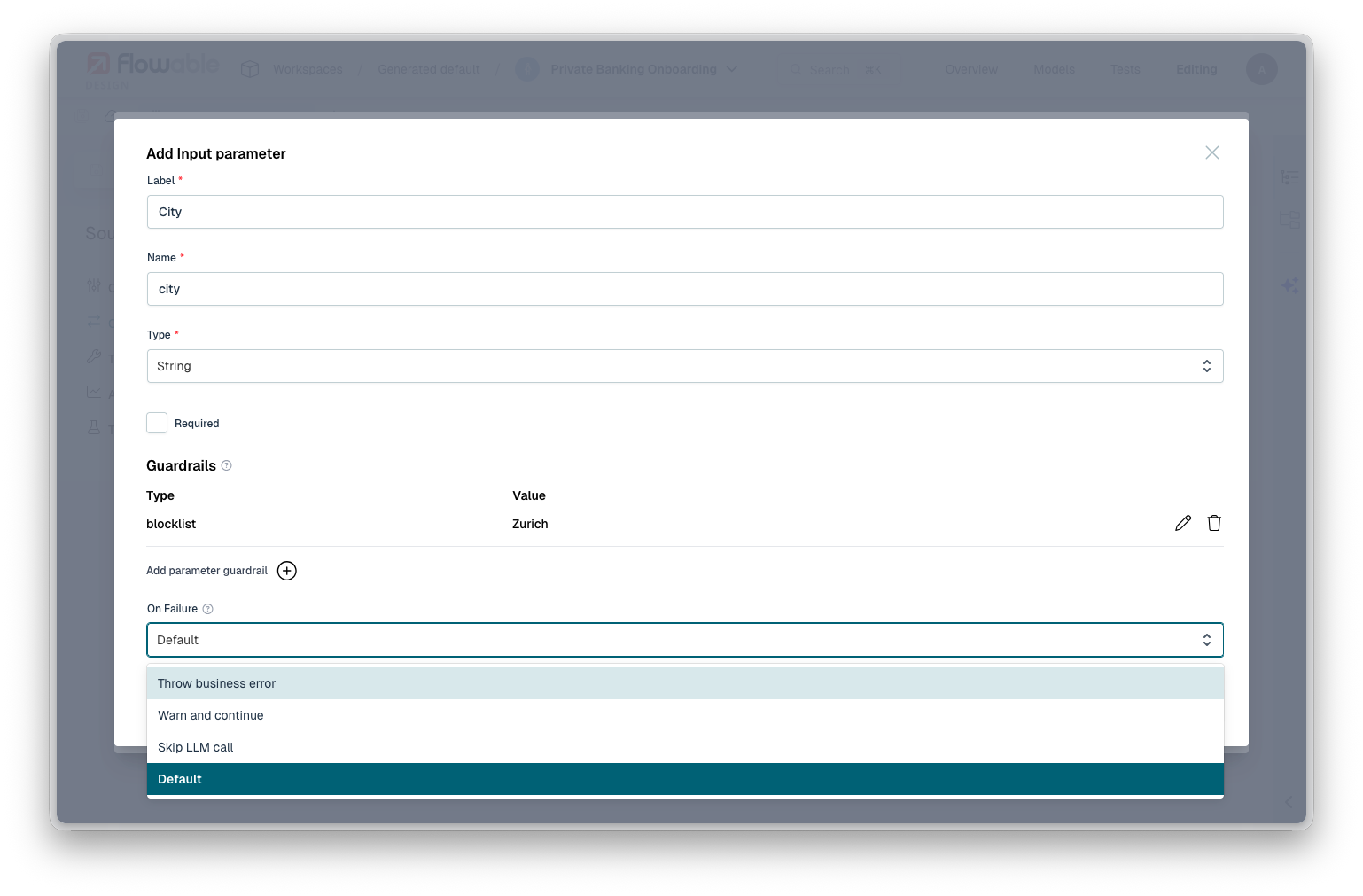
- Deterministic input and output guardrails: rule-based checks that validate content without invoking an LLM, including minimum and maximum values, regex patterns, block- and allowlist and more.
- Guardrail agents (policy agents): an LLM-based judge that evaluates content against a natural-language policy and returns a pass or fail verdict, for safety, tone and compliance. Define your own rules in a Policy Agent which is then configured as a guardrail.
- Service registry guardrails: delegate a guardrail check to a registered service, so existing validation, classification or moderation services can act as guardrails.
- Sanitization: guardrails that clean or redact content rather than only blocking it, so a run can continue with safe input or output.
- Skip the LLM call on trigger: a triggered input guardrail short-circuits before the model runs, saving cost and removing risk.
- Choose the outcome: a triggered guardrail can warn and continue, or throw a business error.
- Layered: Combine multiple guardrails for a stronger safety net.
Why it matters
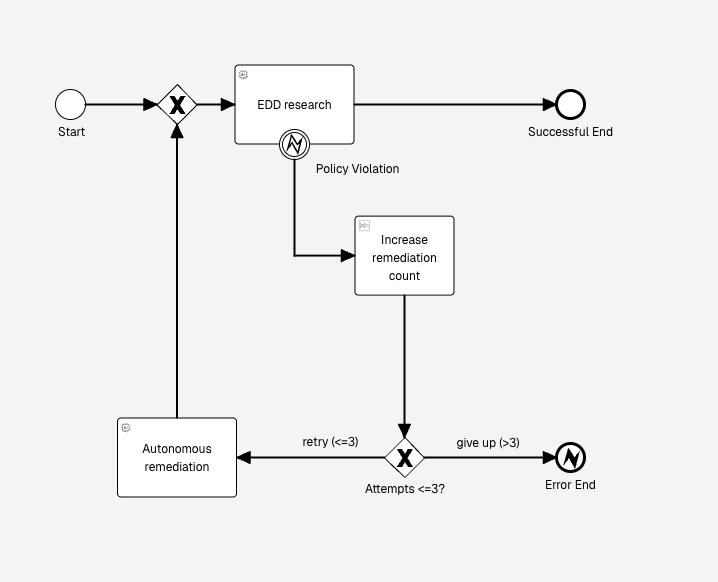
Autonomy is only adoptable when it is governable, and a single check is rarely enough. Layering deterministic rules, policy agents, service-based checks and sanitization lets an organisation match the guardrail to the risk, block the cheap and obvious cases without a model call, and reserve the LLM judge for nuanced policy. Because a triggered guardrail can raise a business error, it becomes visible to the business logic surrounding the agent, which can handle it appropriately.
How it works
Guardrails are configured on the agent, on the input path, the output path, or both. When one is triggered you choose its behavior: warn and continue, or throw a business error. That business error is engine-neutral, so it can be caught by a BPMN error boundary event or a CMMN fault sentry, and the handling can be specific to the guardrail that fired based on the error code. One triggered guardrail might retry with corrected input, another might route to a person, another might end the run. Flowable provides ready-to-use service model connectors for popular content moderation APIs, such as OpenAI Moderation, Presidion PII Detection, LLM Guard and Guardrails AI. These connectors can be downloaded from our documentation and imported into your app in Flowable Design.
Visibility and metrics
Every guardrail evaluation is tracked in the agent timeline, alongside the prompts, tool calls and responses of the run, so you can see which guardrail ran, what it decided, and whether content was sanitized. Guardrail metrics, such as how often a guardrail triggers and the overall pass rate, are also collected into the agent operations dashboards, so trends are visible at a glance. See Agent observability and Hub on-premise and operations for those dashboards.
Example
An AI agent handles incoming requests. A deterministic input guardrail rejects anything over a size limit before any model runs. A sanitization guardrail strips known sensitive patterns from the input. A policy agent then checks the request is in scope. On the way out, an output guardrail throws a business error if the draft reply discloses internal information. The case model catches that specific error, sends the draft back for one automatic rewrite, and escalates to a reviewer if it triggers again.